Generative AI is moving fast, with scaling laws visibly playing out. What will the next few years of deep learning bring us, in terms of real world impact outside of tech/software? I’ve been hearing some bold predictions for disruption. I think about this a lot, since my job is to help the world do beneficial, counterfactually necessary, science projects. If LLMs will just up and replace or transform large swaths of scientific research anytime soon, I need to be aware.
This is not to mention being concerned about AI safety and disruptive AI impacts in general. Some of the smartest people I know have recently dropped everything to work on AI safety per se. I’m confused about this and not trying to touch on it in this blog post.
In thinking about the topic over the last few months, a few apparently useful frames have come up, though they still need some conceptual critique as well, and I also have no claim to novelty on them. I’d like to know where the below is especially wrong or confused.
A possible unifying frame is simply that ~current generation AI models, trained on large data (and possibly fine-tuned on smaller data), can often begin to recapitulate existing human skills, for which there is ample demonstration data, at a “best of humanity” level. There will be some practical limitations to this, but for considering the effects it may be useful to take this notion quite seriously. If this were true quite generally, then what would be the implications of this for science?
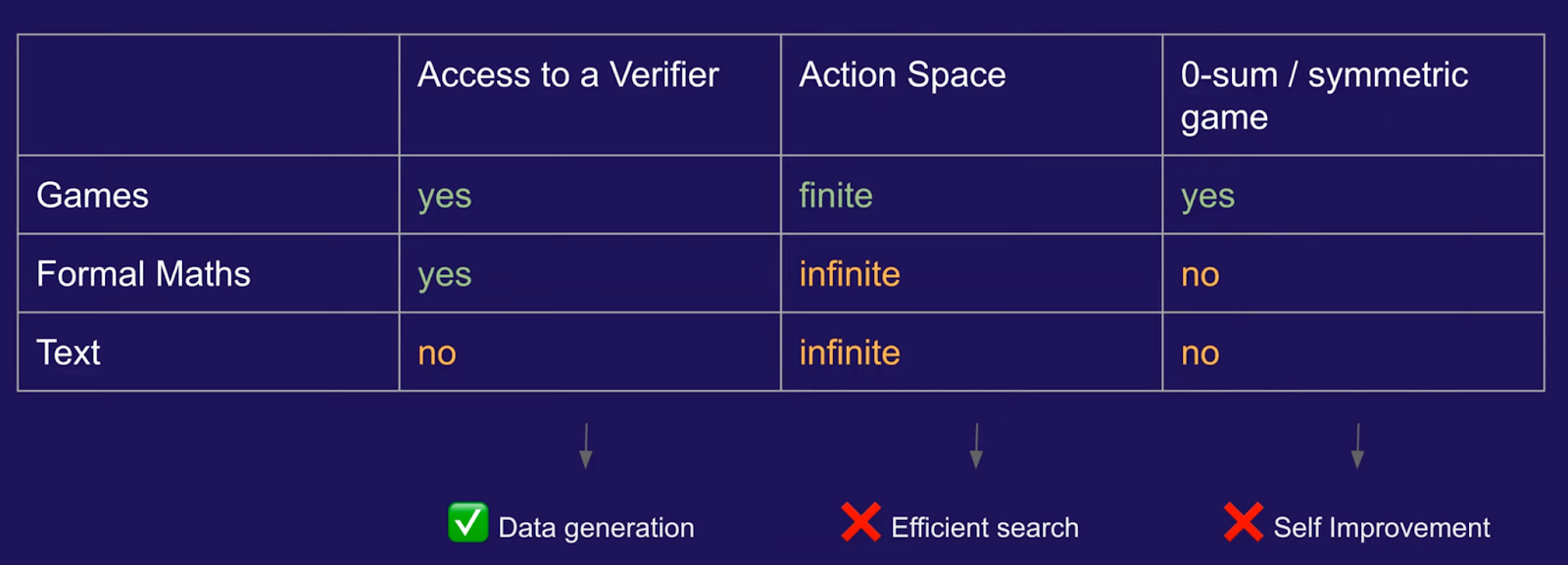
Type 1, 2 and 3 skills
Let’s begin with a distinction between “Type 1, Type 2, and Type 3” skills.
For some skills (Type 1), like playing Go, that are closed worlds, we’ve seen that models can get strongly superhuman by self-play or dense reinforcement learning (RL).
This will probably be true for some scientific areas like automated theorem proving too, since we can verify proofs once formalized (e.g., in the context of an interactive theorem prover like Lean), and thus create entirely within the software a reinforcement-learning-like signal not so different from that from winning a game. So the impact on math could be very large (although there are certainly very non-trivial research challenges along the way).
For many other skills (Type 2), there isn’t an easily accessible game score, simulation or RL signal. But there is ample demonstration data. Thus, GPT-3 writing essays and DALL-E synthesizing paintings. For these skills, a given relatively untrained person will be able to access existing “best of humanity” level skills in under 10 seconds on their web browser. (The extent to which reinforcement learning with human feedback is going to be essential for this to work in any given application is unclear to me and may matter for the details.)
So roughly, the impact model for Type 2 skills is “Best of Existing Skills Instantaneously in Anyone’s Browser”.
What are some emerging Type 2 skills we don’t often think of? Use of your computer generally via keyboard and mouse. Every tap on your phone. Every eye movement in your AR glasses. Every vibration of the accelerometer in your smartwatch. The steps in the design of a complex machine using CAD software.
Let’s suppose that near-term AI is like that above, just applied in ~every domain it can be. This probably will have some limitations in practice, but let’s think about it as a conceptual model.
Routine coding has elements of Type 2 and elements of Type 1, and is almost certainly going to be heavily automated. Many more people will be able to code. Even the best coders will get a productivity boost.
Suppose you have a Type 2 skill. Say, painting photo-realistic 3D scenes. A decent number of humans can do it, and hence DALL-E can do it. Soon, millions of people will do prompt generation for that. Enough people will then be insanely good at such prompt generation that this leads to a new corpus of training data. That then gets built into the next model. Now, everyone AI-assisted is insanely good at the skilled prompt generation itself, with nearly zero effort. And so on. So there is clearly a compounding effect.
Even more so for skills closer to Type 1. Say you have an interactive theorem prover like Lean. Following the narrative for Type 2 skills, a GPT-like system learns to help humans generate proofs in the interactive prover software, or to generate those proofs fully automatically. Then many humans are making proofs with GPT. Some are very good at that. Then, the next model learns how to prompt GPT in the same way, so now everyone can do proofs easily at the level of the best GPT-assisted humans.
Then, the next model learns how to do proofs at the level of the best GPT-assisted model of GPT-assisted humans? But even more so, because with automatic verification of proofs you can get an RL-like signal, without a human in the loop. You can also use language models to help mathematicians formalize their areas in the first place. Math, in turn, is a fantastic testbed for very general AI reasoning. Fortunately, at least some people think that the “math alignment problem” is not very hard, and it will have a lot of applications towards secure and verified software and perhaps AI safety itself.
These figures from Stanislas Polu’s talk at the Harvard New Technologies in Mathematics Seminar are pretty illustrative of how this formal math based testbed could be important for AI itself, too:
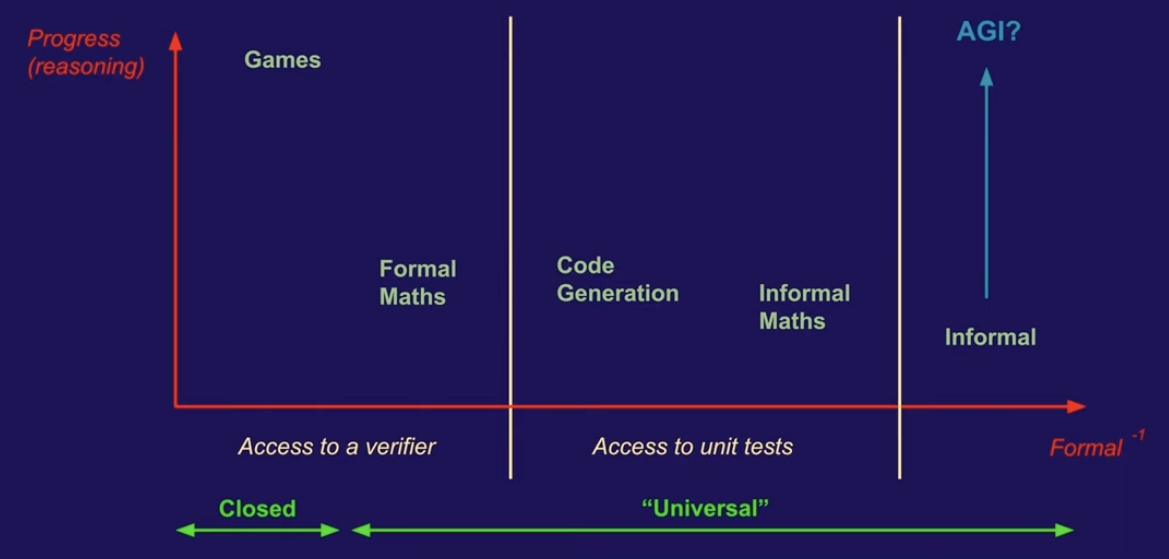
What about, say, robotics? The impact on robotics will likely be in significant part via the impact on coding. The software engineers programming robots will be faster. Many more people will be able to program robots more effectively.
But wait, is it true that the robotics progress rate depends mostly on the time spent by people writing a lot of code? Possibly not. You have to actually test the robots in the physical world. Let’s say that the coding part of robotics progress is highly elastic relative to the above “Best of Existing Skills Instantaneously in Anyone’s Browser” model of AI-induced changes in the world, and speeds by 10x, but that the in the lab hardware testing part of robotics is less elastic and only speeds by 2x. Let’s suppose that that right now these two components — the highly elastic coding part of robotics R&D, and the less elastic in the lab testing part — take about the same amount of time, R. That’s R/2/2 + R/2/10 = 3x speedup of robotics overall.
These numbers may be completely wrong, e.g., Sim2Real transfer and better machine vision may be able to reduce a lot more in-the-lab testing than I’m imagining, but I’m just trying to get to some kind of framework for writing back of the envelope calculations in light of the clear progress in language models.
Suppose that the above factors lead soon to 3x increased rate of progress in robotics generally. Once this 3x speedup kicks in, if we were 30 years away from robots that could do most of the highly general and bespoke things that humans do in a given challenging setting, such as a biology lab, we are now perhaps roughly
[10 years of accelerated robotics progress away: to get the baseline general robotics capability otherwise expected 30 years from now]
+ [say one (accelerated) startup lifetime away: from adapting and productizing that to the very specific bio lab use case, say 2 years]
+ [how long it takes this accelerated progress to kick in, starting where we are now, say 2 years]
+ [how long it takes for bio at some reasonable scale to uptake this, say another 2 years].
So that means we are perhaps about 10 to 15 years away from a level of lab automation that we’d be expecting otherwise 30+ years from now (in the absence of LLM related breakthroughs), on this simple model.
Let’s say this level of automation lets one person do what 10 could previously do, in the lab, through some combination of robotics in the lab per se, software control of instruments, programming of cloud labs and external services relying on more bespoke software-intensive automation. Is that right? I don’t know. Note that in the above, this is still dominated by the general robotics progress rate, so to the extent that AI impacts robotics progress other than just via speeding up coding, say, or that my above numbers are too conservative, this could actually happen sooner.
We haven’t talked about Type 3 skills yet. We’ll come back to those later.
Elastic and inelastic tasks relative to general automation
What about science generally? Here I think it is useful to remember what Sam Rodriques recently posted about
https://www.sam-rodriques.com/post/why-is-progress-in-biology-so-slow
namely that there are many factors slowing down biology research other than the brilliance of scientists in reading the literature and coming up with the next idea, say.
Consider the impact of the above robotic lab automation. That’s (in theory at least) very helpful for parts of experiments that are basically human labor, e.g., cloning genes, running gels. The human labor heavy parts of R&D are very elastic relative to the “Best of Existing Skills in Anyone’s Browser” model of near term AI impacts, i.e., they respond to this change with strong acceleration. A lot of what is slow about human labor becomes fast if any given human laborer has access to a kind of oracle representing the best of existing human skills, in this case represented by a robot. Consider, for example, the time spent training the human laborer to learn a manual skill — this disappears entirely, since the robot can boot up with that skill out of the box, and indeed, can do so at a “best of humanity” level.
Certain other parts of what scientists do are clearly at least somewhat elastic relative to “Best of Existing Skills in Anyone’s Browser”. Finding relevant papers given your near-term research goals, digesting and summarizing the literature, planning out the execution of well-known experiments or variants of them, writing up protocols, designing DNA constructs, ordering supplies, hacking together a basic data visualization or analysis script, re-formatting your research proposal for a grant or journal submission template, writing up tutorials and onboarding materials for new students and technicians, making a CAD drawing and translating it to a fabrication protocol, designing a circuit board, and so on, and so forth.
Given the above, it is easy to get excited about the prospects for accelerated science (and perhaps also quite worried about broader economic disruption, perhaps the need for something like universal basic income, and so on, but that’s another subject). Especially considering that what one lab can do depends positively on what other labs can do, since they draw continually on one another’s knowledge. Should we see an increased rate of progress, but not just linearly, rather in a change to the time constant of an exponential? How should we model the effect of the increased single-lab or single person productivity, due to the effects of broad Best of Existing Skills Instantaneously in Anyone’s Browser capabilities?
But what about parts of scientific experiments that are, e.g., as an extreme example, something like “letting the monkeys grow old”? These are the “inelastic” parts. If we need to see if a monkey will actually get an age-related disease, we need to let it grow old. That takes years. This speed isn’t limited by access to previously-rare-and-expensive human skills. The monkey lifecycle is just what it is. If we want to know if a diagnostic can predict cancer 20 years before it arises, then at least naively, we’ll need to wait 20 years to find out if we’re right. We’ll be able to come up with some surrogate endpoints and predictors/models for long-timescale or other complex in-vivo biology (e.g., translation of animal findings to humans), but they’ll still need to be validated relative to humans. If we want in-silico models, we’ll need massive data generation to get the training data, often at a level of scale and resolution where we don’t have existing tools. That seems to set a limit on how quick the most relevant AI-accelerated bio progress could be.
Sometimes there are clever work-arounds, of course, e.g., you don’t necessarily need to grow full plants to usefully genetically engineer plants, and in the “growing old” example, one can use pre-aged subjects and study aging reversal rather than prevention/slowing. In fact, coming up with and validating those kinds of work-arounds may itself be what is ultimately rate-limiting. FRO-like projects to generate hard-to-get ground truth data or tooling to underpin specific uses of AI (like making a universal latent variable model of cellular state) in science may be one fruitful avenue. Concerned that the clinical trial to test a new cell therapy is going to be expensive and dangerous – maybe try a cell therapy with a chemical off-switch instead. How inelastic must inelastic be, really?
Type 3 skills?
Finally, what about “Type 3” skills? On the one hand, someone could say, “science” requires more than just existing “best of humanity level” skills. What scientists do is NOT just practice skills that other people already have. It is not enough to just make routine and fast on anyone’s web browser something that humanity at large already knows, because science is about discovering what even humanity at large does not know yet. What scientists are doing is creating new ideas that go beyond what humanity in aggregate already knows. So “science” is not a Type 1 or Type 2 skill, one might say, it is a “Type 3 skill”, perhaps, i.e., one that does not come from simply imitating the best of what humanity at large already knows and has documented well, but rather extends the all-of-humanity reach out further. Furthermore, as Sam points out, a lot of the literature is basically wrong (or severely incomplete) in bio, so logic based on the literature directly to scientific conclusions or even correct hypotheses may not get you all that far. Furthermore, LLMs currently generate a lot of incorrect ramblings and don’t have a strong “drive towards truth” as opposed to just a “drive to imitate what humans typically do”.
On the other hand, much of what scientists actually spend their time on is not some essentialized novel truth generating insight production galaxy brain mind state per se, but rather things like making an Excel spreadsheet to plan your experiment and the reagents you need to order and prepare. Enumerating/tiling a space of possibilities and then trying several. Visualizing data to find patterns. Finding and digesting relevant literature. Training new students so they can do the same. Furthermore, as mentioned, in certain more abstruse areas of science, like pure math, we have the possibility of formal verification. So theoretical areas may see a boost of some kind too to the extent that they rely on formal math, perhaps seeing in just a few years the kind of productivity boost that came from Matlab and Mathematica over a multi-decade period. A lot of science can be sped up regardless of whether there are real and important Type 3 skills.
Are there real Type 3 skills? Roger Penrose famously said that human mathematical insight is actually uncomputable (probably wrong). But in the above it seems like we can accelerate formal math in the context of interactive theorem provers. Where is the Type 3 math skill? In the above we also said that a lot of what seems like Type 3 science skill is just an agglomeration of bespoke regular skills. I’d like to hear people’s thoughts on this. I bet Type 3 skills do very much exist. But how rate limiting are they for a given area of science?
More bespoke, and direct, AI applications in science
This is not to mention other more bespoke applications of AI to science. Merely having the ability to do increasingly facile protein design has unblocked diverse areas from molecular machine design to molecular ticker-tape recording in cells. This is now being boosted by generative AI, and there are explicit efforts to automate it. (Hopefully, this will help quickly bring a lot of new non-biological elements into protein engineering, and thus help the world’s bioengineers move away from autonomously self-replicating systems, partially mitigating some biosafety and biosecurity risks.)
There isn’t the space here to go over all the other exciting boosts to specific areas of science that come from specific areas of deep learning, as opposed to more general automation of human cognition as we’re considering with language models, their application to coding, and so on. Sequence to sequence models for decoding mass spectrometry into protein sequences, predicting antigens from receptor sequences, stabilizing fusion plasmas, density functional theory for quantum chemistry calculations, model inference, representations of 3D objects and constructions for more seamless CAD design… the list is just getting started. Not to mention the possible role of “self-driving labs” that become increasingly end-to-end AI driven, even if in narrower areas? It seems like we could be poised for quite broad acceleration in the near term just given the agglomeration of more narrow deep learning use cases within specific research fields.
Inhabiting a changing world
We haven’t even much considered ML-driven acceleration of ML research itself, e.g., via “AutoML” or efficient neural architecture search, or just via LLMs taking a lot of the more annoying work out of coding.
A recent modeling paper concludes that: “We find that deep learning’s idea production function depends notably more on capital. This greater dependence implies that more capital will be deployed per scientist in AI-augmented R&D, boosting scientists’ productivity and economy more broadly. Specifically our point estimates, when analysed in the context of a standard semi-endogenous growth model of the US economy, suggest that AI-augmented areas of R&D would increase the rate of productivity growth by between 1.7- and 2-fold compared to the historical average rate observed over the past 70 years”
In any case, it seems that there could be a real acceleration in the world outside of software and tech, from generative AI. But “inelastic” tasks, and fundamentally missing data, within areas like biology, may still set a limit on the rate of progress, even with AI acceleration of many scientific workflows. It is worth thinking about how to unblock areas of science that are more inelastic.
In this accelerated world model, I’m (somewhat) reassured that people are thinking about how to push forward beneficial uses of this technology, and how to align society to remain cooperative and generative in the face of fast change.
Acknowledgements
Thanks to Eric Drexler, Sam Rodriques and Alexey Guzey, as well as Erika De Benedectis, Milan Cvitkovic, Eliana Lorch and David Dalrymple for useful discussions that informed these thoughts (but no implied endorsement by them of this post).
Thanks for the thoughtful post! Couple of quick replies:
1. On the names of the types. In cognitive-behavioral therapy, there are four types of learning:
1) Classical conditioning – increasing or decreasing the frequency of behaviors
2) Operant conditioning – shaping behaviors
3) Social learning – observing others behaviors
4) Cognitive learning – eg developing schemas
Eg see here: https://www.simplypsychology.org/a-level-approaches.html
It sounds like “Type 1” could be subsumed under classical and operant conditioning; “Type 2” is social learning; and “Type 3” is cognitive learning, ie schema development. But maybe it doesn’t fully map.
2. Recently I’ve been working with teams to write some systematic review papers on topics related to brain banking. Eg: https://actaneurocomms.biomedcentral.com/articles/10.1186/s40478-019-0799-y
On the one hand, it would be fantastic if this work could be automated (although as you point out, also concerning in the absence of a good system of safeguards, because this would be an enormously powerful AI technology).
But I don’t think that this is likely to happen anytime soon (at least on the timescale of a few years). There are so many barriers – identifying the problem, paradigm-creating (on a small scale, not trying to be grandiose, I just think this is necessary for approaching any scientific problem), figuring out which papers/findings to trust and which ones to down-weight, etc.
I think this is mostly cognitive learning, and I think it is probably the primary bottleneck to progress in science. I know people are working on automating literature reviews but I’ve tried a couple of them and so far and they’re not very good.
In other words, I think that there is some “type 3″/cognitive learning stuff that is based on purely reading the literature and thinking that is also inelastic unless we are talking about superintelligence.
My guess is that if literature reviews on complex topics can be done in a better than human way, then it is difficult to predict what happens in society next.